然而,随着AI智能产品的广泛应用,用户也开始面临一系列顾虑:AI智能产品是不是真的智能?它是否能够应用于我的业务?安全性是否有保障?这些问题催生了对AI智能产品综合能力评测的迫切需求。
AI智能产品测评
安全是发展的前提
虽然行业已存在多类测试平台,但在测什么、如何测、常态化测评支撑、资源投入等方面难以满足客户特定需求。安全是发展的前提
1. 客观评估框架缺失
当前AI智能产品测评面临的最大难题是缺乏一个客观且公认的评估框架。由于没有统一的标准,不同的评测平台和开发者使用各自的方法和指标,导致评测结果难以比较和验证。
2. 测评指标和方法不统一
由于缺乏统一的测评指标和方法,AI智能产品的评测往往依赖于特定的数据集或场景,这些可能与实际需求脱节。这导致评测结果无法真实反映AI智能产品在实际业务中的应用效果。
3. 标准化测评平台缺失
大部分平台缺乏可视化界面,并且测评流程复杂繁琐。完整的评估通常需要耗费大量算力和时间成本,难以支撑复测和多并发测试。
4. 测评结果滞后
由于大模型技术与安全威胁的快速演变,测评平台的数据集和评估方法往往难以及时更新。这种滞后性导致现有平台无法反映AI智能产品的最新能力情况和风险态势。
5. 测评流程效率低
许多开放类问题测评仍需要依赖经验丰富的团队辅助。此外,评估结果的判定和报告生成也往往需要借助工具和平台,进一步增加了人力和资源成本。
三大维度
助力AI智能产品高效应用
面对这些挑战,永信至诚依托在数字安全测评领域的深厚技术积累与业务实践成果,构建春秋AI测评「数字风洞」平台,以春秋AI大模型为核心,基于标准化测评数据和海量业务场景模版,实现对AI智能产品智能度、安全度和匹配度的综合测评,通过以模测模、以模强模,简化测评流程,提高测评效率。助力AI智能产品高效应用
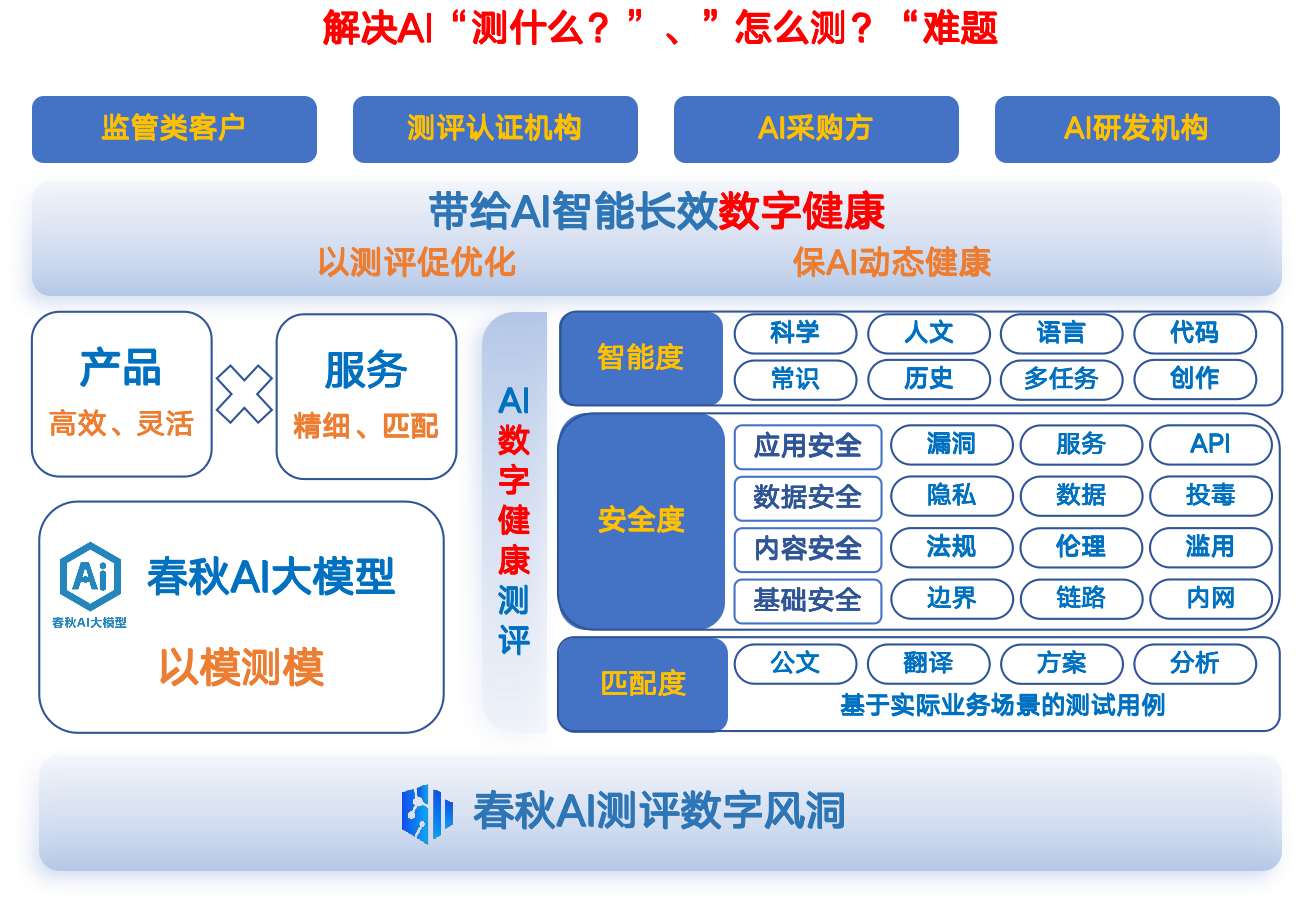
智能度测评
评估AI智能产品的认知和处理能力
智能度测评重点关注评估AI智能产品在理解、推理和知识应用方面的表现。平台内置了覆盖18个知识领域和100万+测评题目的智能评估体系,能够测评从基本知识应用到复杂推理能力的具体表现。同时,我们也关注AI智能产品是否能够胜任真实场景任务,并通过测评AI智能产品的问答能力、知识补全能力、推理能力及工具学习能力等,进行AI智能产品的“智商”评估。帮助企业了解产品的实际认知能力,确保在业务场景中被准确应用。评估AI智能产品的认知和处理能力

安全度测评
评估AI智能产品应用的潜在风险
安全度测评关注的是AI智能产品使用过程中的潜在风险,包括数据隐私、系统安全、输出合规性和伦理性。平台集成了超过10万条安全检测数据和300多种攻击载荷模板,通过模拟多种攻击手段测试产品的应对能力,确保其符合法律法规和伦理准则,以及在多环境变化下仍能维持高安全标准。此外,平台还创新性地引入了AI智能产品“血缘”相似度检查。通过分析分词器、模型架构、参数权重和安全抗性,平台可以揭示被测产品与已知开源模型的相似性,有助于识别潜在的安全风险,增强了对模型来源和行为了解的透明度。评估AI智能产品应用的潜在风险

匹配度测评
测评AI智能产品能否满足业务需求
匹配度测评旨在为AI智能产品在特定行业和场景中的应用提供有效支持。平台允许客户根据实际需求自定义测试任务,验证模型在行业特定任务中的模组能力。通过对模型的场景化测试,春秋AI测评「数字风洞」能够评估AI智能产品是否能顺利对接实际业务流程。此外,平台还提供多模型对比功能,帮助用户快速选择最适合自己业务场景的产品,从而保证AI智能体的业务应用性。测评AI智能产品能否满足业务需求
典型行业应用
某金融客户智能客服合规测评
某金融客户智能客服合规测评
为了提升客服效率,减少人工服务成本,某银行一直使用智能客服服务客户,但在合规和安全性上遇到了巨大挑战。为此,该银行选择了春秋AI测评「数字风洞」进行评估,以保障智能客服产品的安全合规性和业务适配性。
首先,春秋AI测评「数字风洞」对智能客服的金融知识储备和推理能力进行了评估。平台发现该产品在常规问题回答上表现良好,但在特定金融法规解读和风险分析上存在知识盲点,从而帮助银行明确了模型优化方向。
其次,平台利用攻击载荷对智能客服平台进行了多轮测试,包括隐私保护和内容合规性方面的严格考察。通过一系列高强度测试,平台确认了模型具备良好的风险识别和应对能力,为客户提供了充分的合规保障。
在整个测评任务中,平台生成了符合银行客户服务场景的测试数据,并模拟银行业的典型问答场景,对AI智能产品的应用适配性进行验证,为AI智能产品的定向优化提供了标准与方向。
在智能化的浪潮中,春秋AI测评「数字风洞」以独立、客观的第三方视角,为各行业用户提供了覆盖智能度、安全度和匹配度的多维度测评平台,推动AI技术的安全、合规、高效应用,为数字化、智能化转型保驾护航。
